Methods
We introduce a dataset based on biographical records (with a presence in more than 15 Wikipedia language editions) that can be used to study spatial and temporal variations in our historical records. This dataset allows us to link cultural domains, to places and time. We also quantify biographies with different levels of visibility using two previously accepted measures of historical impact: the number of Wikipedia language editions a biography is features in, and the Historical Popularity Index (HPI). The dataset is updated every three months, to include new people that crossed the threshold and include more recent pageview data.
List of pages:
We collect the full list of pages within the scope of the WikiProject Biography as of December 2015 with more than 15 Wikipedia language editions. We complement this set with all the instances of the class human from the Wikidata dump from December 2015, with more than 15 Wikipedia language editions. We then use a simple classifier to filter out articles about more than one person (e.g. bands or comedy duos). This gives us a total of 49395 articles.
Filtering by the number of language editions lets us focus on historical characters that have achieved global relevance, as expressed in the documentation of these biographies in a large number of languages. The L>15 threshold helps us exclude characters that have high local popularity but little global popularity. Examples of biographies with high L include characters of enormous historical weight, such as Isaac Newton, Van Gogh and Aristotle, who have articles in more than 150 Wikipedia language editions, but also more recent contributors to global culture such as Gabriel Garcia Marquez, Albert Camus or Pablo Neruda, who have articles in more than 50 Wikipedia language editions. Example of popular forms of local culture that do not make the L>25 cut include American football players, in the case of the U.S. or T.V. personalities that are only known in the Spanish speaking world.
Properties:
All memorability indicators were collected using Wikipedia APIs. Birth and death parameters were collected from the Wikipedia infobox, when available, or from Wikidata.
The occupation was collected by training a SVM algorithm using the Pantheon 1.0 dataset enriched with new manually curated biographies that account for the new occupations. The probability ratio between the first and second occupations predicted by the model are provided as an accuracy measure for the predicted occupations. The model has an in-sample accuracy of 87%.
Based on the birth_place and the list of ‘cities with more than 15000 people’ from geonames, we assigned each person to a (controlled) set of towns. Then, cities were created by grouping towns using a modification of the DBSCAN spatial clustering algorithm on top of the ‘cities with more than 15000 people’ from geonames. Our modification includes information about the population of each town: it starts always from the biggest town and connects a new town to the cluster only when it has a smaller population than the source town (this splits urban centers that are very close to each other, and makes the algorithm more stable to parameter variation). Finally, we manually verify the resulting cities that have more than once capital.
Modern countries were assigned through the town. We restricted ourselves to countries that are either UN members or participate in at least one UN specialized agency. For example, Palestine is not a UN member, but it participates in UNESCO, therefore we consider it as part of our classification. On the other hand, Turkish Republic of Northern Cyprus does not participate in any UN specialized agency and therefore is considered as part of Cyprus for the effects of our dataset. We will update this aggregation when new countries are recognized as UN member states
Based on birth_place and the birth_year, we collected the birth_civ using the polygons from geacron. When a polygon could not be found, such as for the birthplace of Pocahontas, we assigned the closest polygon for that year.
Measures of Historical Relevance:
Following the work by Yu et. al., Pantheon 2.0 measures the global relevance of historical characters using two measures. The simpler of the two measures, which we denote as L, is the number of different Wikipedia language editions a biography of a character is featured on. The most sophisticated measure, the Historical Popularity Index (HPI), corrects L by adding information on the age of the historical character—as a proxy for breaking the barrier of time—the concentration of PageViews among different languages—to discount characters with PageViews mostly in a few languages—the coefficient of variation in PageViews—to discount characters that have short periods of popularity—and the number of non-english Wikipedia pageviews—to reduce any English bias even further. At the level of countries, or cities, we aggregate the HPI of its historical characters to obtain the Historical Cultural Production Index (HCPI).
The HPI combines the number of languages L, the effective number of languages L*, the age of the historical character A, the number of PageViews in Non-English Wikipedias v_NE (calculated in 2016), and the coefficient of variation in PageViews in all languages between CV (also calculated in 2016). In simple terms L∗ provides us with the number of different languages associated with a biography after taking into account the concentration of pageviews in each language. For instance, a historical character with L=100 but with 99.9% of her pageviews in one language would have a L∗~1, since the high concentration of pageviews means that she has a presence mostly in one language. By the same token, a historical character with L=100 but with pageviews distributed evenly among all languages will have an L∗=100.
Technically, for each biography we define each of these variables as:
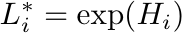
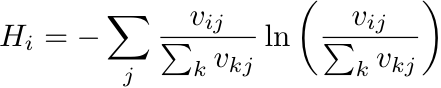
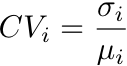
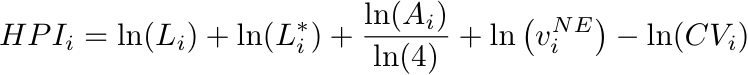
Where v_ij is the total number of pageviews of character i in language j, sigma_i is the standard deviation in pageviews in all languages across time, and mu_i is the average.
Biases
As any quantitative research, our work has limitations that need to be taken into account when interpreting the data. We emphasize the need to interpret our data as valid only in the narrow context of the sources used to compile these datasets. By acknowledging these limitations, we make clear that we do not propose this method to represent an unbiased view of the world. In this section, however, we will not discuss the implications of each bias and limitation in our dataset, but simply, will describe and classify all of the biases that are part of this data collection effort. We recognize four major sources of bias:
- The use of Wikipedia as a data source.
- The use of place of birth to assign locations.
- The use of biographies.
1. Wikipedia as a data source:
The Pantheon 2.0 dataset has all the biases inherent in using Wikipedia as a primary data source, therefore our results should be interpreted as statements about the picture of history that is representative only of the people who edit the more than 250 language editions of Wikipedia—a literate and digitally empowered elite of knowledge enthusiasts. Wikipedia editors have an English Bias, a Western Bias, and they tend to be highly educated and computer savvy. They are also more prevalent among richer countries with Internet access. We remind the reader, however, that by using data from all Wikipedia language editions we are effectively reducing a bias that would favor the local culture of English speakers.
“Wikipedia editors are not considered to be a representative sample of the world population, but a sample of publicly-minded knowledge specialists that are willing and able to dedicate time and effort to contribute to the online documentation of knowledge. Wikipedia editors have an English Bias, a Western Bias, a gender bias towards males, and they tend to be highly educated and technically inclined. They are also more prevalent among developed countries with Internet access. Wikipedia also has a considerable bias in the inclusion of people from different categories. This bias could be the result of the differences in the notability criteria in Wikipedia for biographies from different domains, or from systematic biases within the Wikipedia community. Finally, Wikipedia also has a recency bias, since current events and contemporary individuals typically have greater prominence in the minds of Wikipedia contributors than events from the past.”
2. Place of birth to assign locations:
Individuals were assigned to geographic locations using their place of birth up to the most fined grained available information. Yet, one important limitation is that the place where an individual was born is often different from the place where that individual made his or her more important contributions. In some case, the contributions are made in a number of places, and the use of places of births is unable to capture where the contributions were made. This is particularly true for athletes who migrate to the world’s most competitive leagues, or artists that move to the artistic centers of their time. In this dataset, the movement of people throughout their lives is not recorded.
3. Use of biographies:
The use of biographies excludes accomplishments where there is not a clear connection between a contribution and an author or creator. These are collective enterprises, where the accomplishments are the results of teams and not isolated individuals. Examples of team accomplishments that are likely to get excluded include music bands or orchestras, or the products produced by a firm.
Resources
There are many good references and resources for those wanting to learn more about global cultural development. Below you can find a list with a few resources including literature, methods and datasets from a number of disciplines and authors. If you find that there is a resource that is missing, please be constructive and send us an email with a reference or link to the resource together with a brief summary of the contribution. That way, we can add it to this page. You can reach us easily at [email protected].
Cultural Anthropology
Rob Boyd and Peter Richerson are an essential reference for anyone interested in the topic of culture and its importance for the development of our species. Their recent book Not By Genes Alone (2008) is a good place to get started with their work [2]. Additional references and material can be found in their personal homepages (Boyd UCLA page and Peter Richerson UC Davis Page)
Mathematical Models of Cultural Evolution
Do you think the study of culture could benefit from mathematical models, such as coupled differential equations? Then, look no further than Luigi Cavalli-Sforza classic work on the topic. Whether you are interested in the transmission of lastnames or religious preferences you will find a model complete with derivations in his 1981 book Cultural Transmission and Evolution [7]. L.L. Cavalli-Sforza was a prolific author who wrote extensively about the evolution of culture as well as the estimation of phylogenetic trees and the spread of human populations, so if you are interested in this topic please do not hesitate to dive into this stream of literature.
Quantitative Estimates of Cultural Production
Prior to the release of the dataset we are making available in this site, the largest linked dataset on cultural development and human accomplishments produced was that published by Charles Murray in his (2003) book Human Accomplishment [4]. Murray collected information from a number of linguistic sources from both the East and West and made this data available, together with a description of the data collection method, in his 2003 book. The book is an essential reference for anyone looking to work or study quantitative approaches estimating the level of cultural production for different regions and eras.
Culturomics
The work on n-grams by Erez Lieberman and Jean-Baptiste Michel has become well known among those working at the intersection of big data, networks, computer science and culture. The work looks at the n-grams (collections of n-characters) contained within the google books collection[8]. You can explore the n-gram viewer by visiting this link.
Works using Wikipedia to Study Culture
Eom and Shepelyansky (2013) used Wikipedia to try to determine whether the fame of historical characters is local or global [9].
Aragon et al. (2012) used Wikipedia to study differences in the links between biographies in different language editions [10].
Skiena and Ward (2013) used the English Wikipedia to create rankings of important historical characters and topics.[11]
Yasseri et al. (2013) used the Wikipedia to study the topics that are more controversial in each language.[12]
References and Endnotes
[1] Edward O. Wilson, The Social Conquest of Earth, Liveright (2012)
[2] The definition of culture as the information transmitted through non-genetic means is a popular definition among scholars in a large number of disciplines. A non-exhaustive list of works that use this definition include (1) Spector, L., & Luke, S. (1996, July). Cultural transmission of information in genetic programming. In Proceedings of the First Annual Conference on Genetic Programming (pp. 209-214). MIT Press, (2) Danchin, É., Giraldeau, L. A., Valone, T. J., & Wagner, R. H. (2004). Public information: from nosy neighbors to cultural evolution. Science, 305(5683), 487-491. (3) Richerson, P. J., & Boyd, R. (2008). Not by genes alone: How culture transformed human evolution. University of Chicago Press.
[3] Francis Fukuyama, Trust, Free Press (1995)
[4] Murray, C. (2003). Human accomplishment. HarperCollins.
[5] Bowlby, John. Charles Darwin: A new life. WW Norton & Company, 1992.
[6] Darwin, Charles. The Autobiography of Charles Darwin. Barnes & Noble Publishing, 2005.
[7] Cavalli-Sforza, L. L., & Feldman, M. W. (1981). Cultural transmission and evolution: a quantitative approach. Monographs in Population Biology, 16, 1–388.
[8] Michel, J.-B., Shen, Y. K., Aiden, A. P., Veres, A., Gray, M. K., Pickett, J. P., … Aiden, E. L. (2011). Quantitative analysis of culture using millions of digitized books. Science (New York, N.Y.), 331(6014), 176–82.
[9] Eom, Y., & Shepelyansky, D. L. (2013). Highlighting entanglement of cultures via ranking of multilingual Wikipedia articles.
[10] Aragon, P., Laniado, D., Kaltenbrunner, A., & Volkovich, Y. (2011). Biographical Social Networks on Wikipedia A cross-cultural study of links that made history. In WikiSym ’12 (pp. 3–6).
[11] Skiena, S., & Ward, C. (2013). Who’s Bigger?: Where Historical Figures Really Rank (p. 408). Cambridge University Press.
[12] Yasseri, T., Spoerri, A., Graham, M., & Kertész, J. (2013). The most controversial topics in Wikipedia: A multilingual and geographical analysis.